H2 Server
리눅스 환경에서 Modern C++(C++17)을 활용하여 개발한 epoll, io_uring, mmap, NGHTTP2, OpenSSL 기반의 고성능 http/2 서버
| 구분 | 내용 |
|---|---|
| 플랫폼 | Linux |
| 개발 도구 및 사용 언어 | g++ 11.4.0, C++, nghttp2 v1.60.0, OpenSSL v3.0.2, liburing2 |
| 개발 기간 | 2025년 3월 ~ 2025년 10월 |
| 저장소 | 바로 가기 |
1. 개요
h2-server는 Modern C++(C++17) 기반의 고성능 HTTP/2 서버 프로젝트이다.
Linux 환경에서 epoll(Edge-Triggered) 기반 비동기 I/O를 처리하고, nghttp2 + OpenSSL을 통해 HTTP/2 요청/응답을 처리한다.
또한 H2C(평문) 모드, mmap 기반 파일 캐시, 멀티스레드 워커 구조를 통해 저지연 파일 서비스와 고부하 환경에서의 처리량 확장을 목표로 개발했다.
이 프로젝트는 단순히 HTTP/2 기능을 구현하는 데 그치지 않고,
이벤트 기반 I/O, TLS 처리, 멀티스레드 확장성, 로드 밸런싱, 정적 분리(static partitioning), completion 기반 처리 모델과 같은 시스템 레벨 설계를 단계적으로 실험·검증하는 데 초점을 두고 발전시킨 개인 프로젝트이다.
초기에는 acceptor → load balancer → worker 구조를 중심으로 한 origin 브랜치를 통해 HTTP/2, TLS, mmap 캐시, 멀티스레드 처리 구조의 기본 타당성을 검증했다.
이후에는 워커 책임과 처리 경로를 더 명확히 분리하고, 특히 H2C 경로에 completion 모델을 도입한 static-partitioning 브랜치를 통해 고부하 환경에서의 처리량 개선을 실험했다.
이 글은 기본적으로 origin 브랜치의 설계와 구현을 상세히 설명하되,
후반부에서는 static-partitioning 브랜치에서의 구조 변화와 최신 성능 결과까지 함께 정리한다.
1.1. 브랜치 개요
이 프로젝트는 하나의 완성된 구현만을 목표로 하기보다,
고성능 HTTP/2 서버 아키텍처를 단계적으로 실험하고 비교·검증하는 과정에 초점을 맞춰 발전시켰다.
origin
acceptor → load balancer → worker구조를 기반으로 한 초기 고성능 설계- HTTP/2, TLS, 멀티스레드 처리, 파일 서비스,
mmap캐시의 기본 구조와 성능 특성을 검증한 베이스라인 브랜치 - 현재 블로그 본문의 구조 설명과 기존 상세 벤치마크는 주로 이 브랜치를 기준으로 한다.
static-partitioning
- 워커 책임과 처리 경로를 더 명확히 분리하기 위해 정적 분리(static partitioning)를 적용한 브랜치
- readiness 중심 접근의 한계를 보완하기 위해 H2C 경로에 completion 모델을 도입
- 최신 구조 개선과 최신 성능 실험 결과가 반영된 브랜치이다.
즉, origin이 서버의 기본 구조와 멀티스레드 확장성의 출발점이었다면,
static-partitioning은 그 위에서 처리 경로를 더 단순하고 고정적으로 다듬어 고부하 throughput을 끌어올리는 실험 단계라고 볼 수 있다.
최신 브랜치 스냅샷 (
static-partitioning)Ubuntu 24.04 환경에서 수행한 최신 benchmark 기준으로,
- 4스레드 이상 구간에서
h2server h2c및h2server h2c-io-uring이nghttpd를 추월- 최고 성능은
h2server_h2c_io_uring_n8- Max QPS: 605,540
- static partitioning 및 completion 모델이 고부하 구간에서 의미 있는 처리량 개선을 보여줌
아래 본문에서는 먼저 origin 기준 구조와 설계 배경을 설명하고, 후반부에서 static-partitioning 결과를 이어서 정리한다.
1.2. 빌드
1.2.1. 소스 코드 빌드
1
2
3
4
5
6
7
# (예) 빌드
cd src
make
# (예) 정리
cd src
make clean
1.2.2. 도커로 빌드
프로젝트를 도커 이미지로 빌드하려면 프로젝트 루트(최상위 디렉터리) 를 다음과 같이 빌드 컨텍스트 위치로 지정해야 한다.
(docker_build/와 src/가 함께 위치한 상위 경로)
1
docker build -t h2-server -f ./docker_build/Dockerfile .
1.3. 실행
1.3.1. 빌드 후 직접 실행
1
2
3
4
5
6
7
# TLS (기본값 포트 443)
cd src
./h2server --port 443 --key ./cert/server.key --cert ./cert/server.crt --threads 4
# H2C (평문)
cd src
./h2server --port 8080 --h2c --threads 4
1.3.2. 도커로 실행
도커로 실행할 때는 환경 변수로 기본 동작을 제어 한다.
| 환경 변수 | 설명 |
|---|---|
RUN_MODE | 실행 모드: h2(TLS) 또는 h2c(평문) |
PORT | 서버 리스닝 포트 (예: 443, 8080) |
THREADS | 워커 스레드 수 |
1) 단일 컨테이너 실행
- TLS(H2) 예시
1
docker run -d --name h2server -e RUN_MODE=h2 -e PORT=443 -e THREADS=4 -p 443:443 h2-server
- 평문(H2C) 예시
1
docker run -d --name h2server-h2c -e RUN_MODE=h2c -e PORT=8080 -e THREADS=4 -p 8080:8080 h2-server
2) docker compose로 실행
docker_build/docker-compose.yml 예시:
1
2
3
4
5
6
7
8
9
h2_server:
image: h2-server
environment:
- RUN_MODE=h2
- PORT=443
- THREADS=4
ports:
- 0.0.0.0:443:443
- :::443:443
실행:
1
2
cd docker_build
docker-compose up -d
H2C로 실행하려면 위 compose 파일에서
RUN_MODE: "h2c",PORT: "8080",ports: ["8080:8080"]로 변경 하면 된다.
1.4. 핸들러 사용법
등록
1
2
server.add_handler(GET, "/files/{file_name}", downloader);
server.add_handler(POST, "/files", uploader);
Request API
| 함수 | 설명 |
|---|---|
reply_ok() | 바디 없이 :status=200 응답 전송 |
reply_ok_with_file() | FileContext를 data source로 연결해 파일 응답 |
reply_404() | 간단한 404 HTML 바디와 함께 :status=404 전송 |
예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int downloader(Request& request) {
StreamData* stream_data = request.stream_data;
const std::string& rel_path = request.rel_path;
if (rel_path.empty()) {
return request.reply_404();
}
auto file = load_file_from_filecache(rel_path);
if (!file) {
return request.reply_404();
}
stream_data->file_ctx.data = file->get_data();
stream_data->file_ctx.size = file->get_data_len();
return request.reply_ok_with_file();
}
2. 자료 구조 (Data Structure Overview)
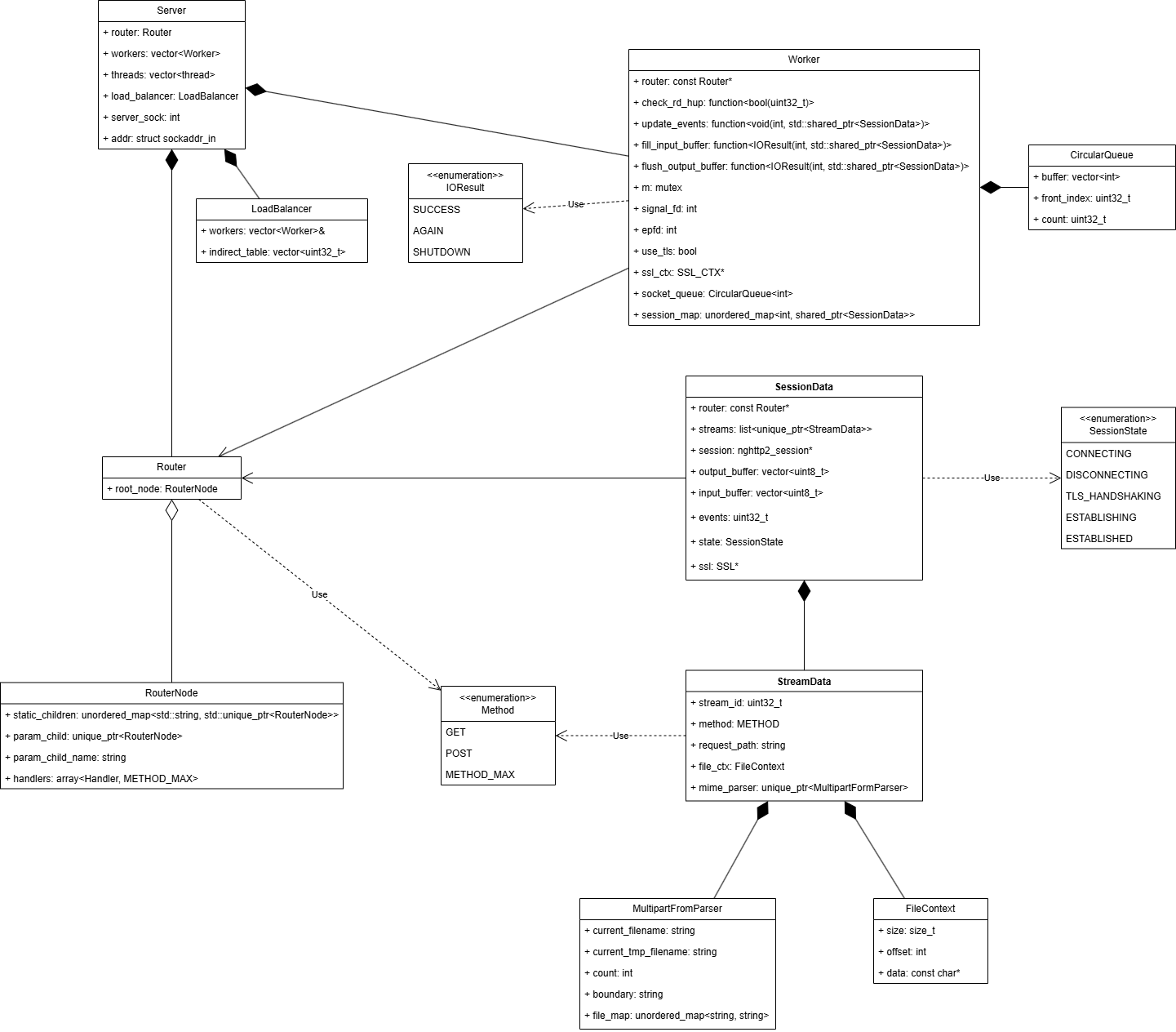
2.1. 주요 자료 구조
1) StreamData — 스트림 레벨 컨텍스트
1
2
3
4
5
6
7
8
9
class StreamData {
public:
uint32_t stream_id;
METHOD method;
std::string request_path;
FileContext file_ctx;
std::unique_ptr<MultipartFormParser> mime_parser;
std::vector<uint8_t> upload_file_buffer;
};
2) SessionData — 세션(소켓) 레벨 컨텍스트
1
2
3
4
5
6
7
8
9
10
11
class SessionData {
public:
const Router* router;
std::list<std::unique_ptr<StreamData>> streams;
nghttp2_session* session;
std::vector<uint8_t> output_buffer;
std::vector<uint8_t> input_buffer;
uint32_t events;
SessionState state;
SSL* ssl;
};
3) Server — accept/분배 + 워커 관리
1
2
3
4
5
6
7
8
9
class Server {
private:
Router router;
std::vector<Worker> workers;
std::vector<std::thread> threads;
LoadBalancer load_balancer;
int epfd, server_sock;
struct sockaddr_in addr;
};
4) Worker — 이벤트 루프 & nghttp2/TLS I/O
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Worker {
private:
const Router* router;
std::function<bool(uint32_t)> check_rd_hup;
std::function<void(int, std::shared_ptr<SessionData>)> update_events;
std::function<IOResult(int, std::shared_ptr<SessionData>)> fill_input_buffer;
std::function<IOResult(int, std::shared_ptr<SessionData>)> flush_output_buffer;
std::mutex m;
int signal_fd, epfd;
bool use_tls;
SSL_CTX* ssl_ctx;
std::queue<int> socket_queue;
std::unordered_map<int, std::shared_ptr<SessionData>> session_map;
};
5) Router — 정적/파라미터 경로 트리
1
2
3
4
5
6
7
8
9
10
11
12
class RouterNode {
public:
std::unordered_map<std::string, std::unique_ptr<RouterNode>> static_children;
std::unique_ptr<RouterNode> param_child; // 같은 레벨에서 파라미터 노드는 1개 제한
std::string param_child_name; // ex) "{id}" -> "id"
std::array<Handler, METHOD_MAX> handlers; // GET/POST 등
};
class Router {
private:
RouterNode root_node;
};
6) File Cache — mmap 기반 zero-copy 지향
1
2
3
4
5
6
7
8
9
10
11
12
class FileContext {
public:
size_t size;
int offset;
const char* data;
};
class MappedFile {
public:
void* data; // mmap 주소
size_t data_len;
};
3. 모듈 구조 (Module Architecture)
아래는 모듈 간 주요 데이터 플로우이다.

3.1. Server
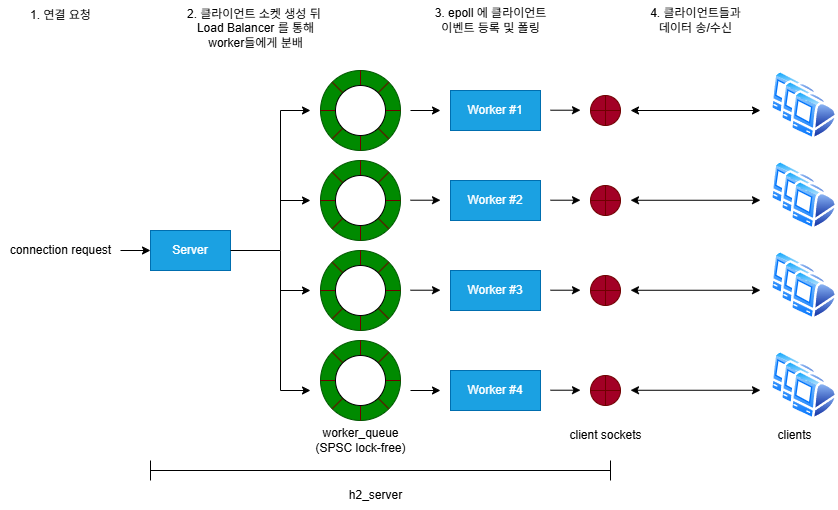
--threads개수만큼 Worker 생성 및 초기화- accept된 클라이언트 소켓을 LoadBalancer를 이용하여 각 Worker 큐에 분배
(eventfd를 통해 워커를 깨워 즉시 처리)
3.1.1. LoadBalancer
다음은 Server 내에 위치하여 입력되는 client 연결 요청을 받아 각 Worker로 분배하는 로드 밸런서이다.
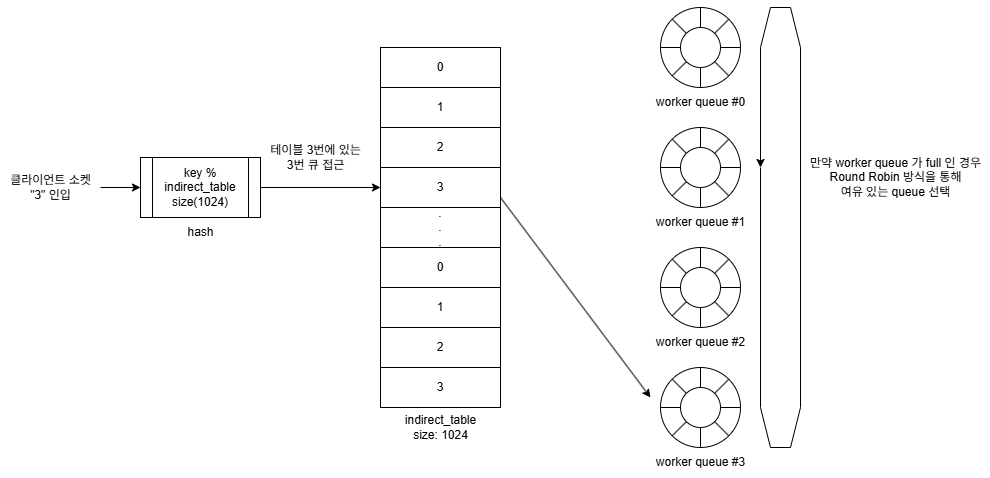
로드 밸런서는 입력된 요청을 받아 해시 연산을 통해 Indirect Table을 참조하여 요청을 전달 할 Worker Queue의 번호를 얻는다.
이때의 Worker Queue는 SPSC(Single Producer Single Consumer) 구조의 lock-free Queue 로써,
그 Worker Queue에 여유가 있는 경우 그대로 요청을 전달 한다.
그러나 만약 선택된 Worker Queue 가 full인 경우, 다른 여유가 있는 Worker Queue를 Round Robin 스케쥴링을 통해 찾아 작업을 요청한다.
이때, 선택된 Worker Queue의 번호는 hash 연산을 통해 접근된 indirect_table의 entry에 갱신 된다.
그리고 이후 이 entry에 접근하는 요청은 새롭게 선택된 Worker Queue로 전달 되게 된다.
만약, Round Robin 스케쥴링을 통해 Worker Queue 들을 한 바퀴 순회 하였음에도 여유 있는 Worker Queue를 발견하지 못하는 경우에는 해당 요청은 버려진다.
- 새롭게 생성된 클라이언트 소켓에 대해
modular연산을 수행하여 indirect_table의 인덱스 값으로 변환 - indirect_table의 엔트리에 있는 Worker Queue 번호를 획득
- 최초 indirect_table에는 Worker Queue의 번호가 순서대로 반복 입력 되어 있다.
- Worker Queue 가 full이 아니라면, 해당 worker queue로 클라이언트 소켓을 전달한다.
- 만약 Worker Queue 가 full 인 경우,
Round Robin스케쥴링을 통해 여분의 Worker Queue 를 찿는다.- 이것은 일종의 fallover 동작으로 볼 수 있다.
- 여분의 Worker Queue 발견 시 방금 접근 했던 indirect_table의 엔트리에 Queue 번호 값을 갱신한다.
- 새롭게 선택된 Worker Queue에 클라이언트 소켓을 전달 한다.
- 만약 여력이 있는 Worker Queue 를 발견하지 못한 경우 생성된 소켓을 close 한다.
- 만약 Worker Queue 가 full 인 경우,
3.2. Worker
- 큐로 전달받은 소켓을 epoll에 등록하고, TLS 핸드셰이크(옵션) → nghttp2 세션을 초기화
- 이벤트 처리:
handle_read:fill_input_buffer→feed_input_buffer(nghttp2_session_mem_recv2)→ 콜백 체인handle_write:fill_output_buffer(nghttp2_session_mem_send2)→flush_output_buffercheck_rd_hup: FIN(RDHUP) 감지 시 안전 종료
3.2.1. worker 내 buffer 처리와 nghttp2 callback 함수들의 호출 flow
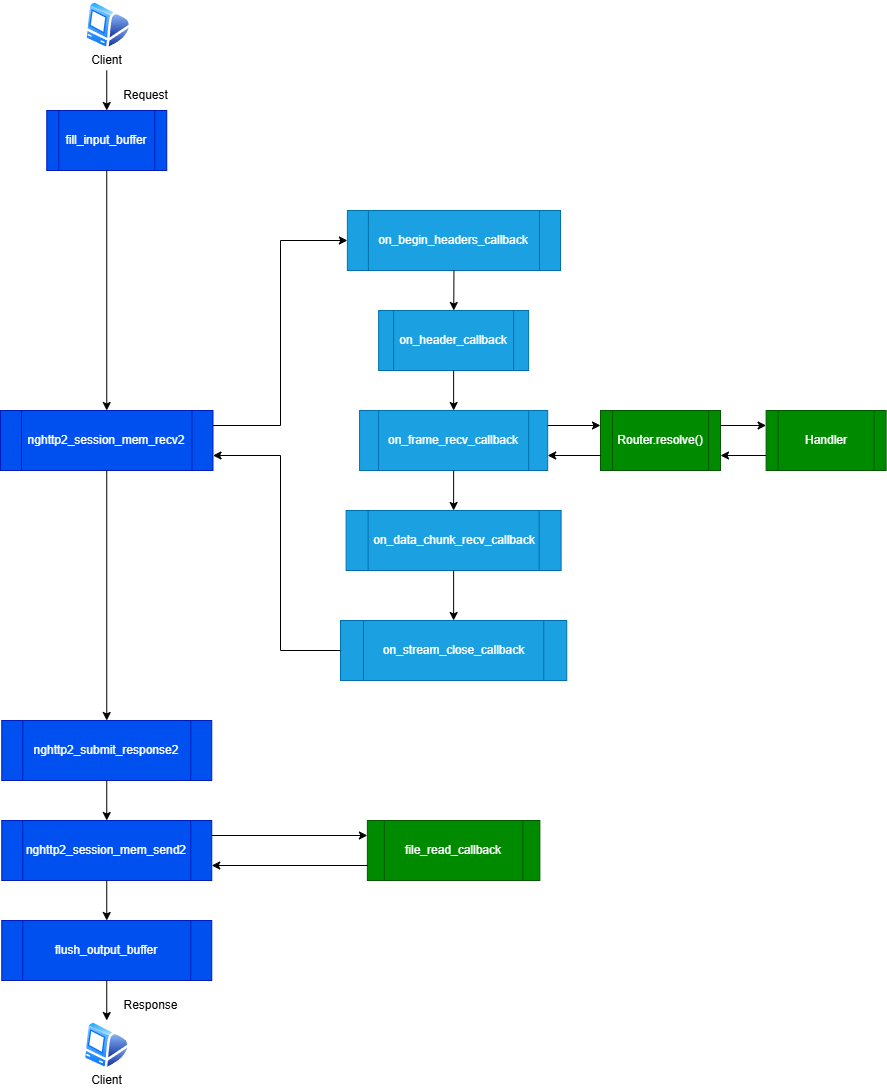
3.2.2. 주요 함수 호출 체인
| 함수명 | 의미 | 트리거 | | :—————————- | :——————- | :——————————- | | fill_input_buffer | 소켓을 통해 수신된 데이터들을 읽어 수신 버퍼에 저장 | 수신 소켓에서 이벤트 발생 시 | |feed_input_buffer| 채워진 수신 buffer 내 내용을 nghttp2 세션 데이터로 feed 할 준비| 더이상 소켓에서 수신할 데이터가 없는 경우 | | nghttp2_session_mem_recv2 | 채워진 buffer 내 데이터들을 nghttp2 라이브러리로 feed | 수신 버퍼에 데이터가 존재하는 경우 | | nghttp2_submit_response2 | 전송할 응답 프레임을 전송 대기큐로 큐잉, data_prd 존재 시 DATA 프레임 생성 | 응답 메시지 전송을 위해 직접 호출 | | nghttp2_session_mem_send2 | 전송 대기 큐 내 응답 프레임을 전송 할 수 있게 직렬화 화여 포인터 반환 | 응답할 수 있는 데이터 존재 시 | |fill_ouput_buffer|포인터가 가리키는 직렬화된 데이터를 출력 버퍼로 복사|| | flush_output_buffer | 출력 버퍼 내 데이터를 소켓을 통해 전송 | 직접 호출 |
3.2.3. 주요 nghttp2 콜백 함수들
| 함수명 | 의미 | 트리거 |
|---|---|---|
on_begin_headers_callback | 헤더 블록 수신 시작 | mem_recv2() 중 |
on_header_callback | 헤더 name/value 수신 | 헤더 수신 때마다 반복 |
on_data_chunk_recv_callback | DATA 바디 청크 수신 | DATA 프레임 수신 중 반복 |
on_frame_recv_callback | 프레임 수신 완료 | 요청 완료 시 Router→Handler 호출 |
on_stream_close_callback | 스트림 종료 | 스트림 close 요청 수신 시 |
3.2.2. TLS(SSL_CTX)
- ALPN 협상에서
h2만 수락(미지원 시 종료) - TLS 미사용(H2C) 모드에서는 ALPN 협상 생략
3.3. Router
다음 4개 경로가 등록되면 트리는 다음과 같은 형태로 구성된다.
1
2
3
4
POST /files/images/{file_name} : handler_b
GET /files/docs/{file_name} : handler_c
POST /users/{user_num} : handler_d
GET /files/images/{file_name} : handler_a
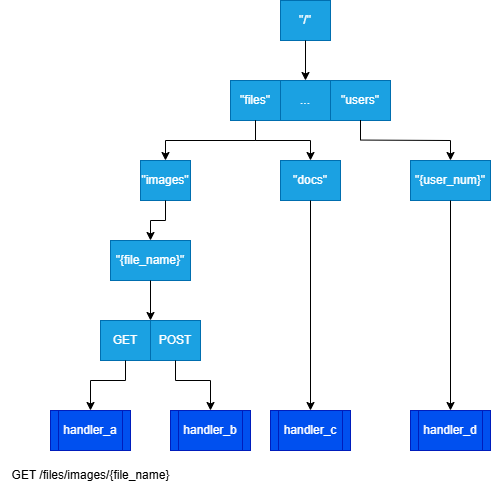
- 정적 경로 우선 → 없으면 파라미터 경로 탐색
- 핸들러는 프로그램 구동 시에만 등록(런타임엔 읽기 전용)
3.4. File Cache
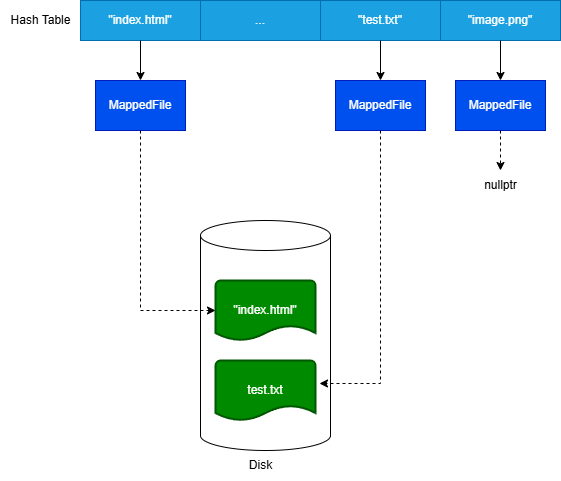
- 디스크 병목 완화 목적의 mmap 캐시
- 주의: 동일 파일에 대한 동시 쓰기 시 경쟁/일관성 문제가 발생할 수 있으므로 운영 시 동기화 정책이 필요하다.
3.5. Multipart Form Parser
- 업로드 요청 처리:
multipart/form-data→ 파일 추출 - 플로우: boundary 파싱 → filename 추출 → temp 쓰기 → 종료 시 rename
- temp 파일명:
h2_tmp_<thread_id>_<count>
3.6. Config Option
| Flag | Type / Default | Description |
|---|---|---|
-p, --port <NUM> | integer / 443 | 리스닝 포트 |
-k, --key <PATH> | path / ./cert/server.key | TLS 개인키(PEM). --h2c면 불필요 |
-c, --cert <PATH> | path / ./cert/server.crt | TLS 인증서(PEM). --h2c면 불필요 |
-n, --threads <NUM> | integer / 1 | 워커 스레드 수 |
--h2c | flag | HTTP/2 cleartext 모드 |
-h, --help | flag | 도움말 출력 |
4. 성능 측정 (Benchmark)
이 프로젝트의 벤치마크는 단순히 “얼마나 빠른가”만 보기 위한 것이 아니라,
아키텍처 변화가 실제로 QPS, tail latency, CPU 사용량, 스레드 확장성에 어떤 영향을 주는지를 확인하기 위한 목적에서 진행했다.
먼저 아래의 기존 측정 결과들은 주로 origin 브랜치 계열의 구조 변화를 기준으로,
Prototype → mmap → TLS → Router → Load Balancer → Acceptor/Worker 순으로 어떤 개선과 트레이드오프가 있었는지를 보여준다.
이후 후반부에서는 별도 섹션으로 static-partitioning 브랜치의 최신 벤치마크 결과를 정리한다.
4.1. 개선 단계별 성능 변화
Prototype → mmap(파일 캐시) 적용 → TLS(https) 적용 → Router 적용 → socket port reuse 멀티스레딩 구조 적용 → acceptor/worker 멀티스레딩 구조 적용 -> Load Balancer 적
주: mmap 도입 전
-c1000 -m100에서는 FD 제한(기본 1024)으로 성공률이 0.1%에 불과.
동일 이슈는libevent-server,nghttpd(≥8 threads)에서도 관측되어ulimit -n상향으로 대응.
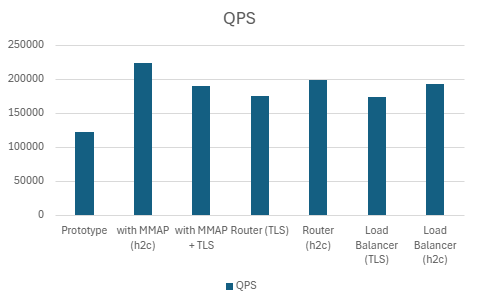
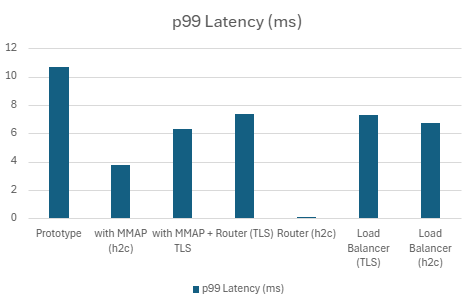
1) h2load -c100 -m10
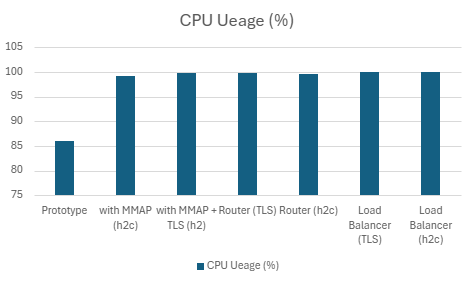
| Server | QPS | P99 Latency (ms) | P90 Latency (ms) | P50 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|---|---|
| Prototype | 122060.232 | 10.674 | 8.9248 | 8.0674 | 98.412 | 7.451171875 |
| with MMAP (h2c) | 224543.5 | 3.7808 | 2.9148 | 2.4816 | 89.632 | 20.30703125 |
| with MMAP + TLS | 190543.634 | 6.327 | 4.626 | 3.074 | 92.728 | 15.84726563 |
| Router (TLS) | 175203.934 | 7.3868 | 5.8176 | 4.7424 | 98.974 | 15.94824219 |
| Router (h2c) | 199643.8 | 0.006327 | 0.004626 | 0.003074 | 92.728 | 0.015475845 |
| LoadBalancer (TLS) | 173702.098 | 7.306 | 5.9562 | 5.0248 | 99.208 | 18.12 |
| LoadBalancer (h2c) | 192895.766 | 6.7044 | 5.5092 | 4.5218 | 99.078 | 9.565039063 |
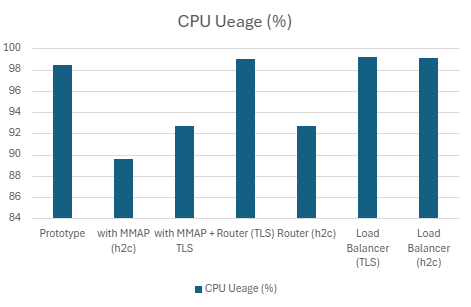
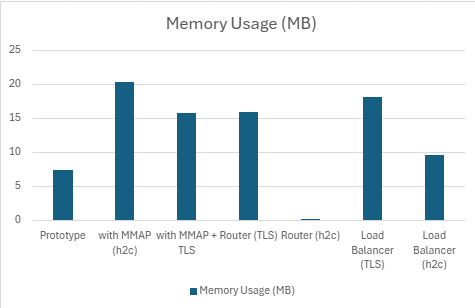
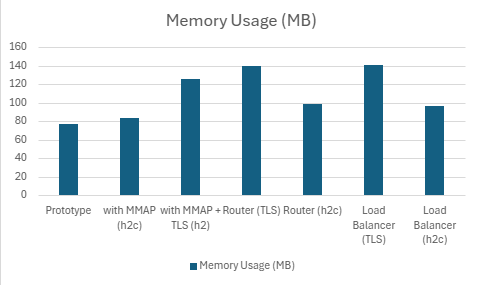
2) h2load -c1000 -m100
| Server | QPS | P99 Latency (ms) | P90 Latency (ms) | P50 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|---|---|
| Prototype | 108745.666 | 968.666 | 891.9512 | 740.1804 | 85.978 | 76.84316406 |
| with MMAP (h2c) | 361051.334 | 290.2608 | 276.253 | 270.2988 | 99.236 | 84.17207031 |
| with MMAP + TLS | 340922.308 | 324.6172 | 290.5728 | 277.5948 | 99.892 | 125.9441406 |
| Router (TLS) | 218128.414 | 505.9948 | 473.1074 | 458.968 | 99.81 | 140.4175781 |
| Router (h2c) | 226110.666 | 486.169 | 453.9088 | 448.7806 | 99.536 | 98.51445313 |
| Load Balancer (TLS) | 205574.332 | 547.7828 | 508.3812 | 486.7182 | 99.942 | 141.19 |
| Load Balancer (h2c) | 221886.068 | 514.821 | 474.6454 | 445.1006 | 99.938 | 96.4296875 |
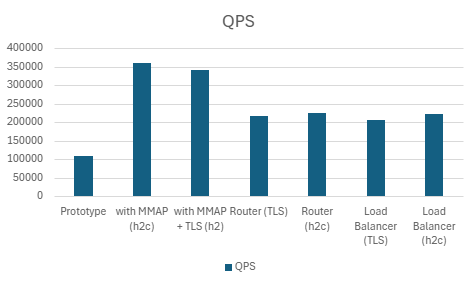
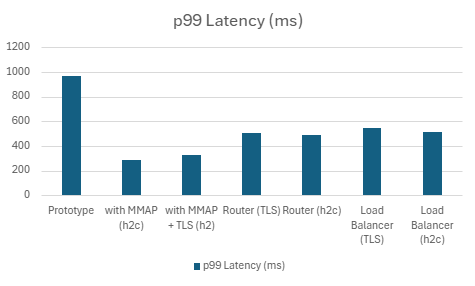
4.1.1. Socket Port Reusing vs Acceptor/Worker
개요
SO_REUSEPORT 옵션을 사용하면 동일한 포트 번호에 대해 여러 개의 리스닝 소켓을 동시에 bind 할 수 있다.
본 HTTP/2 서버 아키텍처에서는 다음 두 가지 모델을 비교하였다.
- Socket Port Reusing 방식 (커밋 해시:
b2985a2d81e4db92e00b7171dd9ebb93b4bc2df3) - Acceptor/Worker 방식 (커밋 해시:
db6af3ddcdcf329e5a72bc0df9b7c236284df795)
💡 참고: 본 절의 내용과 수치는 Load Balancer 도입 이전 버전을 기준으로 한다.
Socket Port Reusing 방식
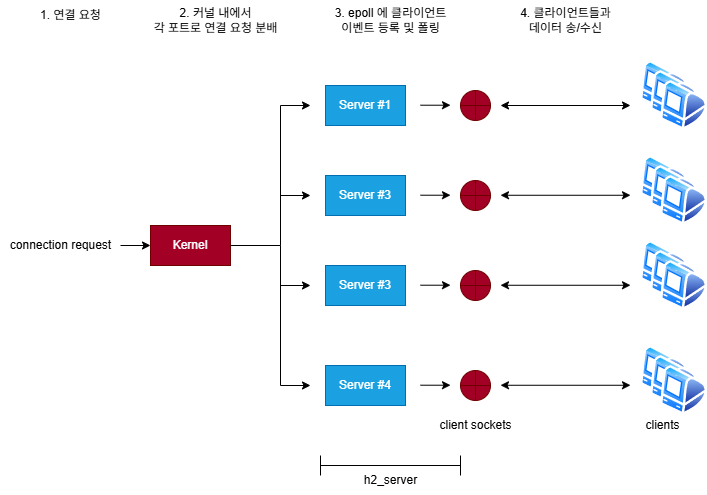
참고: Socket Port Reusing 방식은 현재 버전의 구조를 갖추기 이전에 사용되었던 설계이며,
해당 구현은 커밋 해시e4c03916b3ca61d2a82fe72fe4b67f0ddd75ab05에 포함되어 있다.
특징
- 각 스레드 또는 프로세스가 독립적인 리스닝 소켓을 생성하고
SO_REUSEPORT를 설정함. - 커널은 동일 포트에 바인딩된 소켓들을 reuseport 그룹으로 묶어 관리.
- 커널이 접속 요청을 리스닝 소켓 단위로 로드밸런싱해 분배함.
장점
- 구현 난이도가 낮고 구조가 단순함.
- Accept 경합을 줄여 락 경쟁이 거의 없음.
- 커널 내에서 로드밸런싱이 수행 됨.
단점
- 애플리케이션 레벨에서 연결 분배를 직접 제어하기 어려움.
- 서버 구조가 커지면 역할 분리·모듈성 측면에서 확장성이 떨어짐.
Acceptor/Worker 방식
특징
- Acceptor 스레드
- 오직
accept()만 담당 - 새 연결 생성 후 그 FD를 worker에 전달
- 오직
- Worker 스레드
- Session(HTTP/2 프레임 처리, SSL, I/O 등) 전담
장점
- 역할 분리가 명확해 구조적 일관성/가독성 우수.
- 애플리케이션 레벨에서 connection dispatch 전략을 자유롭게 설계 가능.
- 확장성 및 유지보수성이 매우 높음.
단점
- 구현 복잡도가 socket reuseport 방식보다 높음.
- inter-thread communication(파이프/lock-free 큐 등) 필요.
결론
두 구조는 성능적으로 유사하지만, 본 프로젝트에서는 다음과 같은 이유로 Acceptor/Worker 구조를 택함.
- 역할 분리 및 모듈성 우수
- 유지보수 용이
- 구조 확장에 유리
- Session 핸들링 로직이 Worker로 집중되어 코드 가독성 및 명확성 증가
4.1.1.1. H2
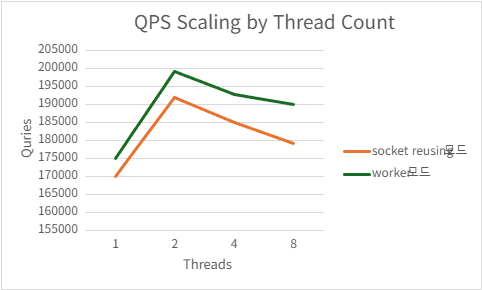
1) h2load -c100 -m10
Port reusing
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 170082.768 | 7.8838 | 98.852 | 16.43515625 |
| 2 | 191969.9 | 4.9168 | 138.792 | 15.86367188 |
| 4 | 185166.968 | 4.157 | 146.418 | 15.86210938 |
| 8 | 179178.1275 | 3.8758 | 162.196 | 15.91289063 |
Acceptor/worker
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 186105.4 | 9.0076 | 98.956 | 15.99785156 |
| 2 | 195737.5 | 5.7036 | 143.214 | 15.89492188 |
| 4 | 179277.368 | 3.4026 | 149.856 | 15.87246094 |
| 8 | 183349.368 | 3.3312 | 169.3 | 15.98984375 |
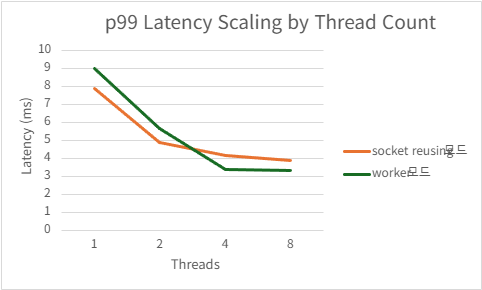
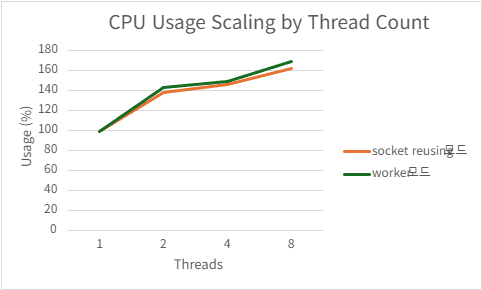
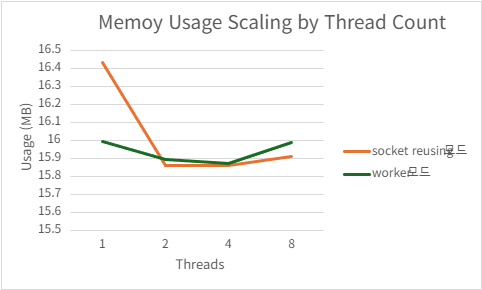
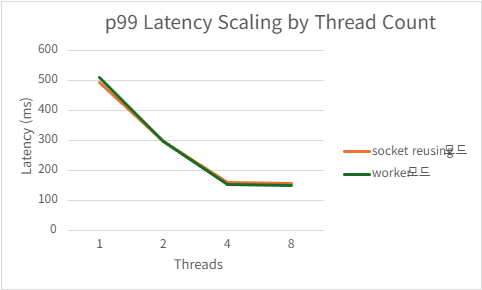
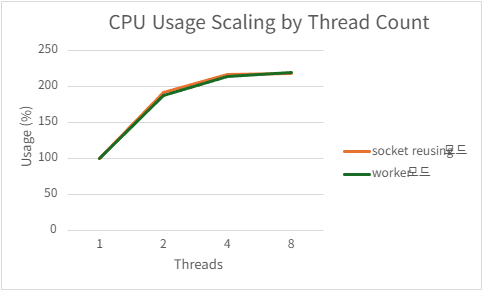
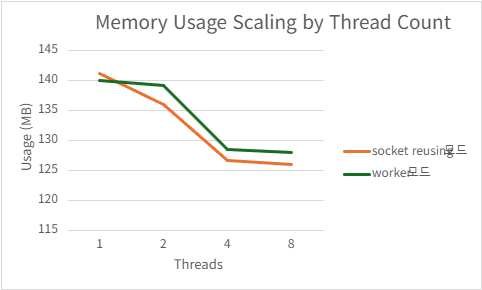
2) h2load -c1000 -m100
Port reusing
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 220103.334 | 495.8666 | 99.726 | 141.2958984 |
| 2 | 399747.666 | 298.155 | 187.066 | 136 |
| 4 | 421299.026 | 160.2804 | 204.244 | 126.6503906 |
| 8 | 417792.915 | 157.9678 | 209.762 | 126.0441406 |
Acceptor/worker
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 217159.334 | 510.0868 | 99.846 | 140.0394531 |
| 2 | 389953.44 | 295.7502 | 186.524 | 139.2839844 |
| 4 | 426597.082 | 153.9212 | 208.794 | 128.4552734 |
| 8 | 423505.2 | 148.8116 | 210.396 | 128.0207031 |
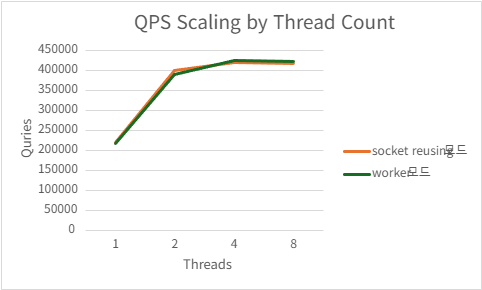
4.1.1.2. H2C
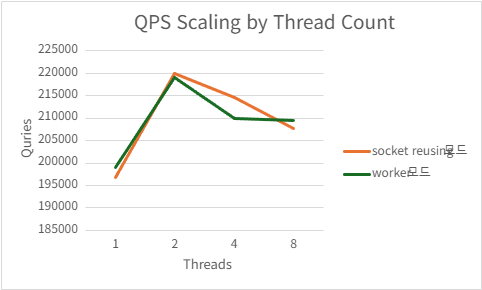
1) h2load -c100 -m10
Port reusing
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 196712.666 | 6.9948 | 98.758 | 9.514257813 |
| 2 | 220055.094 | 4.6052 | 146.156 | 9.423828125 |
| 4 | 214679.334 | 3.329 | 151.404 | 9.4296875 |
| 8 | 207702.494 | 3.5508 | 164.488 | 9.51796875 |
Acceptor/worker
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 199005.834 | 6.3428 | 99.07 | 9.519335938 |
| 2 | 219053.934 | 4.0376 | 140.308 | 9.49453125 |
| 4 | 210013.102 | 3.3358 | 143.344 | 9.295898438 |
| 8 | 209466.56 | 3.5956 | 166.562 | 9.462109375 |
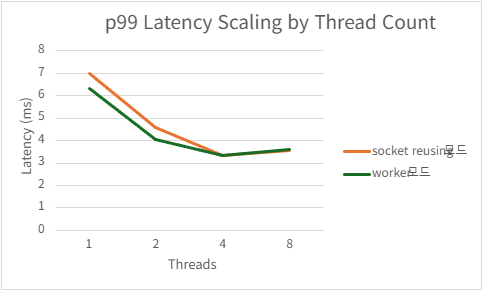
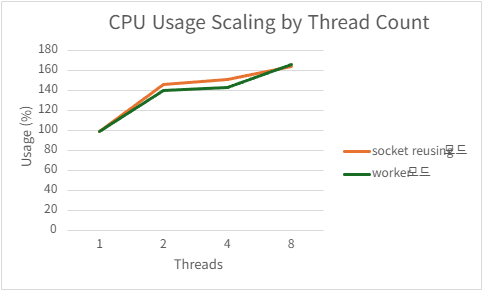
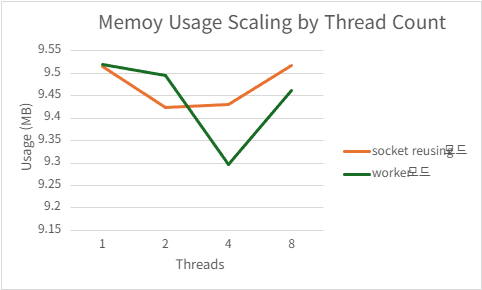
2) h2load -c1000 -m100
Port reusing
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 224862.99 | 384.2416 | 99.626 | 76.52480469 |
| 2 | 404943.208 | 307.5908 | 192.06 | 94.28222656 |
| 4 | 438058.332 | 160.4104 | 217.454 | 89.04765625 |
| 8 | 435534 | 156.368 | 218.666 | 81.909375 |
Acceptor/worker
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 225519.504 | 501.1668 | 99.724 | 97.57636719 |
| 2 | 406958.212 | 281.1706 | 187.632 | 94.61152344 |
| 4 | 451179 | 153.3158 | 214.998 | 89.13046875 |
| 8 | 445782.332 | 146.397 | 219.958 | 80.2796875 |
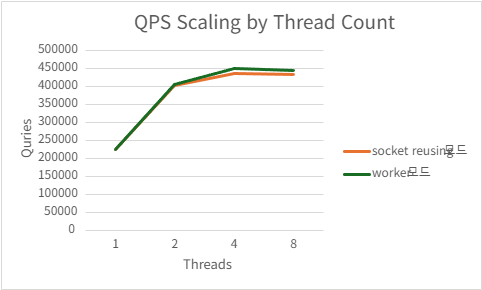
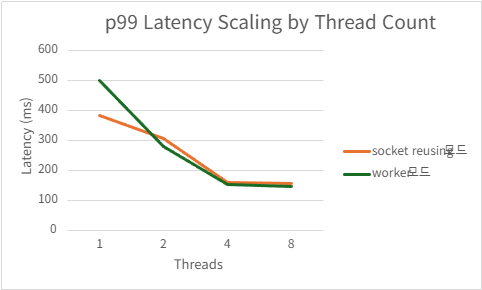
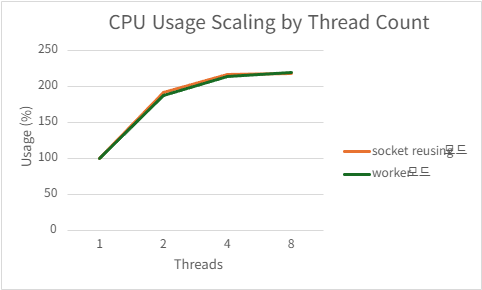
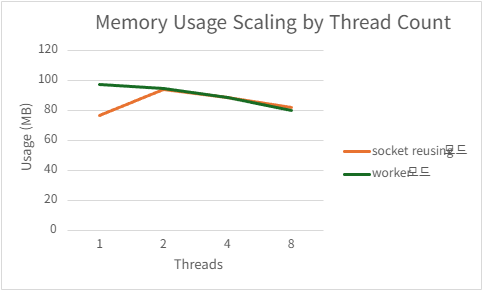
4.2. 서버 프로그램 간 성능 비교
- h2server commit:
c34cd1d9ce9 - nghttpd: nghttp2 v1.60.0
- libevent-server: nghttp2 v1.60.0
요약:
nghttpd는 스레드 증가에 따른 메모리 안정성이 높지만 성능 스케일링 이득은 제한적h2server는 스레드 증가와 함께 CPU/메모리 사용량이 증가하나 처리량도 동반 증가
4.2.1. Single Thread
2server, nghttpd, libevent 간 성능을 비교.
libevent의 경우 h2c 모드를 지원하지 않으므로 h2 테스트에서는 제외.
4.2.1.1. H2
1) h2load -c100 -m10
| Server | QPS | P99 Latency (ms) | P90 Latency (ms) | P50 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|---|---|
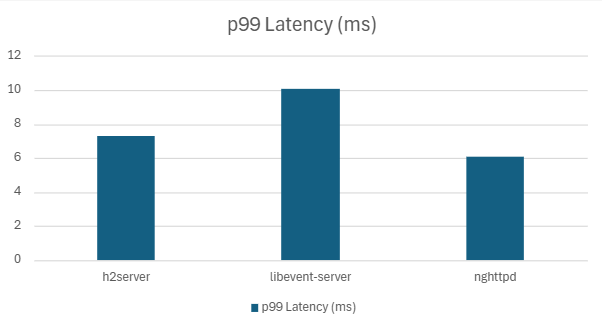
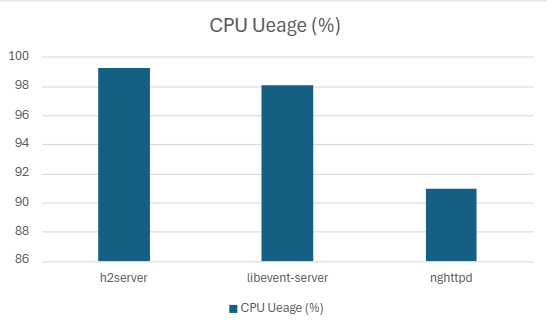
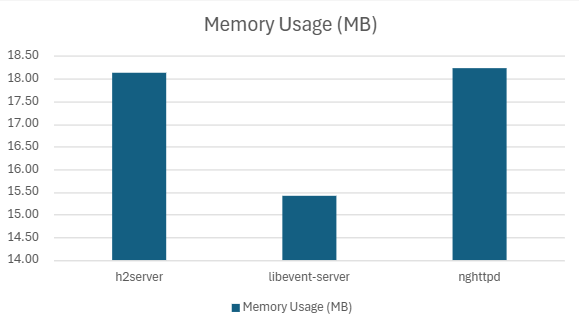
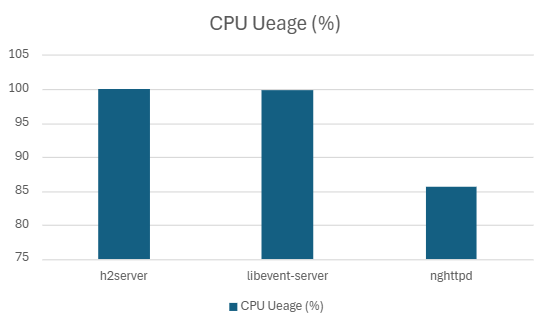
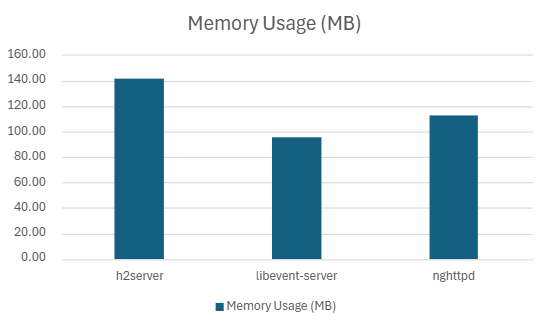
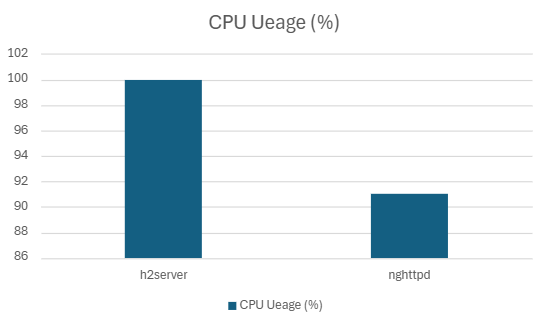
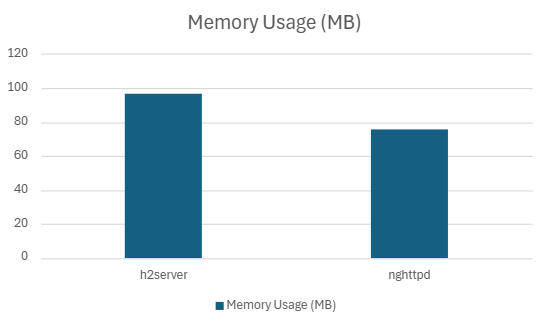
| h2server | 173702.09 | 7.30 | 5.9562 | 5.02 | 99.20 | 18.12 |
| Libevent-server | 154655.1 | 10.07 | 7.18 | 5.50 | 98.02 | 15.41 |
| nghttpd | 181680 | 6.08 | 4.15 | 2.79 | 90.942 | 18.23 |
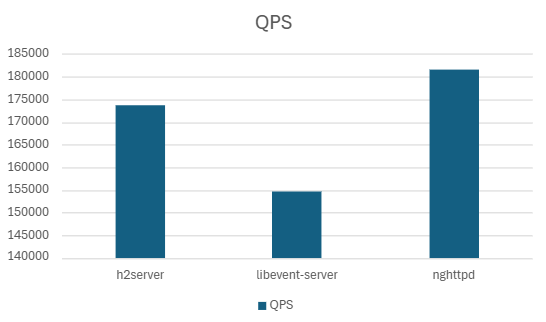
2) h2load -c1000 -m100
| Server | QPS | P99 Latency (ms) | P90 Latency (ms) | P50 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|---|---|
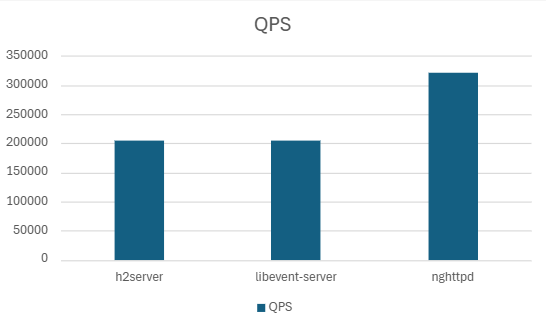
| h2server | 205574.33 | 547.78 | 508.38 | 486.71 | 99.94 | 141.19 |
| Libevent-server | 204798.99 | 541.53 | 507.15 | 479.89 | 99.91 | 95.45 |
| nghttpd | 321848.43 | 235.78 | 166.42 | 157.61 | 85.59 | 112.38 |

4.2.1.2. H2C
1) h2load -c100 -m10
| Server | QPS | P99 Latency (ms) | P90 Latency (ms) | P50 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|---|---|
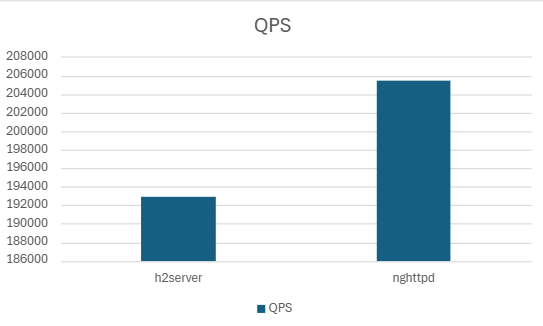
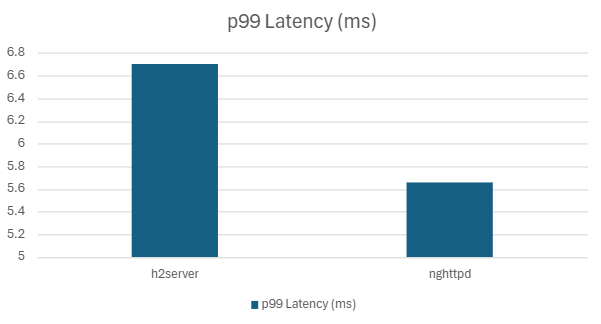
| h2server | 192895.76 | 6.70 | 5.50 | 4.52 | 99.07 | 9.56 |
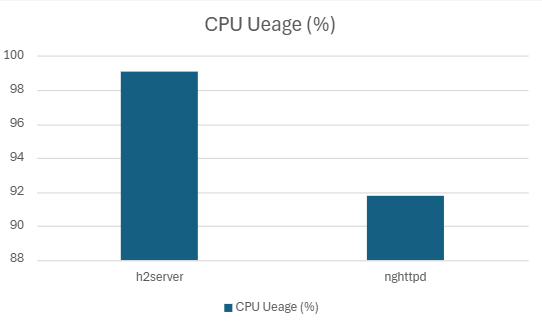
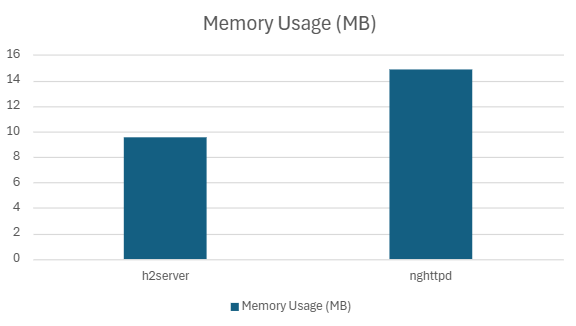
| nghttpd | 205405.52 | 5.65 | 3.94 | 2.48 | 91.77 | 14.84 |
2) h2load -c1000 -m100
| Server | QPS | P99 Latency (ms) | P90 Latency (ms) | P50 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|---|---|
| h2server | 221886.06 | 514.82 | 474.64 | 445.10 | 99.93 | 96.42 |
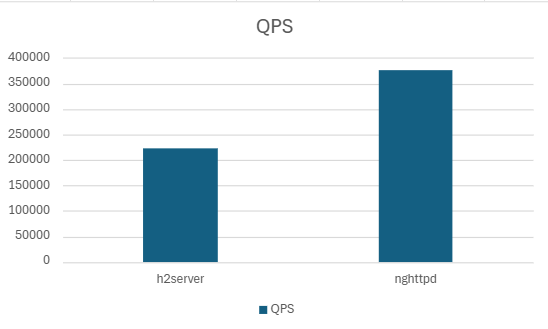
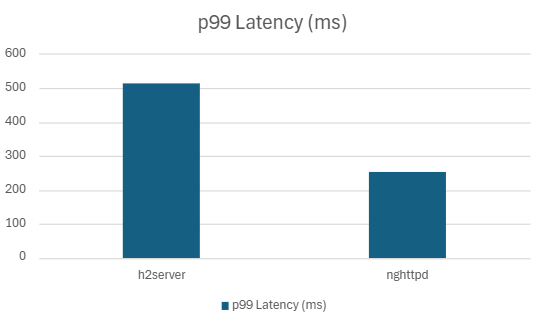
| nghttpd | 375828.33 | 254.24 | 213.16 | 134.79 | 91.04 | 75.29 |
4.2.2. 스레드 스케일링 비교
libevent-server는 멀티스레드 미지원 → 제외nghttpd는 8스레드에서 FD 부족 이슈 →ulimit -n 65535로 상향하여 측정
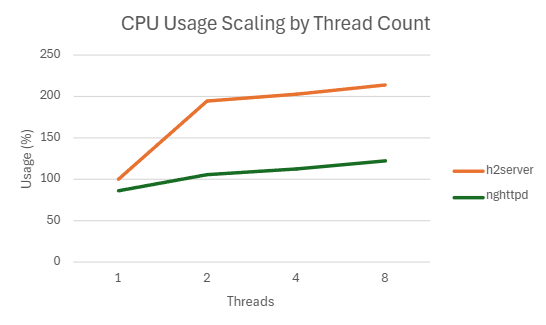
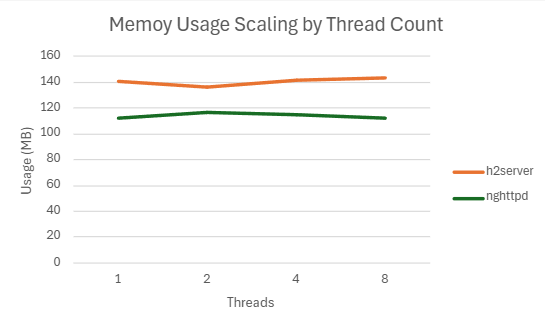
4.2.2.1 H2
1) h2load -c100 -m10
h2server
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
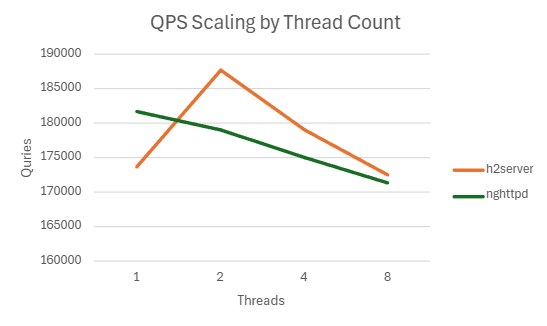
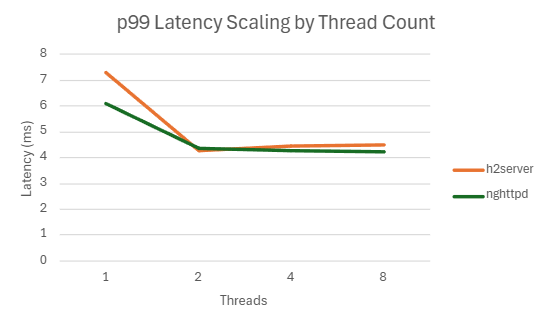
| 1 | 173702.098 | 7.306 | 99.208 | 18.12363281 |
| 2 | 187681.734 | 4.2538 | 139.288 | 18.12070313 |
| 4 | 178973.032 | 4.4518 | 155.91 | 18.06914063 |
| 8 | 172458.585 | 4.4838 | 166.854 | 18.3203125 |
nghttpd
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 181680 | 6.083 | 90.942 | 18.22597656 |
| 2 | 179038.566 | 4.3452 | 108.585 | 18.2668457 |
| 4 | 174970.764 | 4.2538 | 119.614 | 18.61054688 |
| 8 | 171352.502 | 4.23 | 130.3475 | 19.821875 |
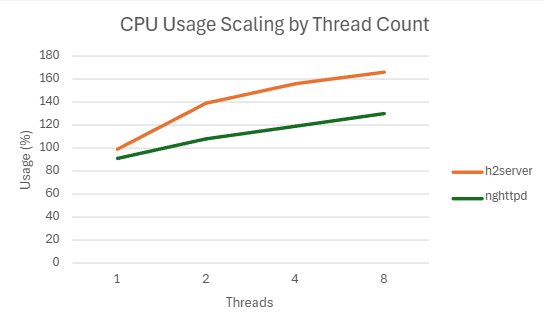
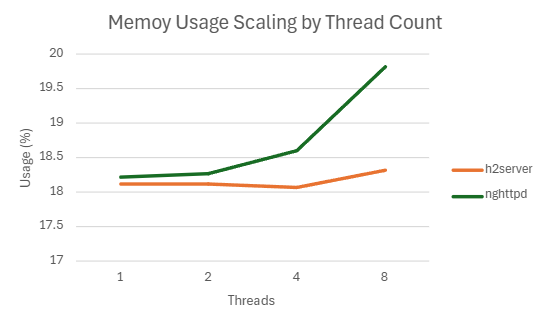
2) h2load -c1000 -m100
h2server
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 205574.332 | 547.7828 | 99.942 | 141.1904297 |
| 2 | 393091.732 | 305.2898 | 194.396 | 136.2841797 |
| 4 | 403797.186 | 157.3542 | 203.208 | 141.8414063 |
| 8 | 404569.212 | 152.979 | 214.93 | 143.1271484 |
nghttpd
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 321848.43 | 235.788 | 85.59 | 112.3808594 |
| 2 | 358788.664 | 188.0264 | 105.616 | 116.7830078 |
| 4 | 367662.9 | 177.935 | 113.07 | 115.0414063 |
| 8 | 348835.566 | 182.8562 | 122.024 | 112.4423828 |
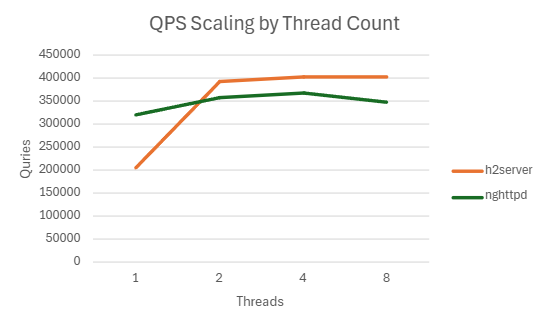
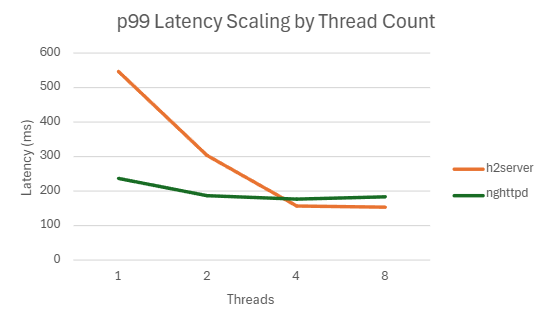
4.2.2.2. H2C
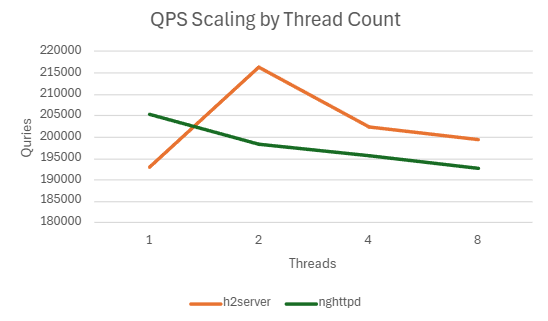
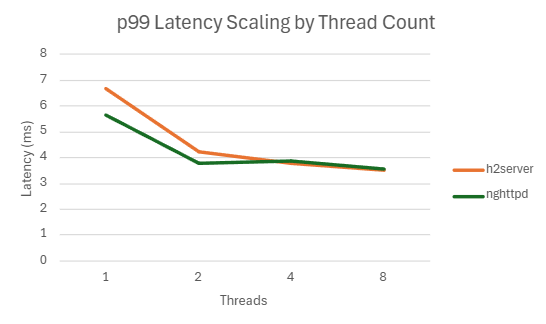
1) h2load -c100 -m10
h2server
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 192895.766 | 6.7044 | 99.078 | 9.565039063 |
| 2 | 216457.4 | 4.2202 | 148.056 | 9.491796875 |
| 4 | 202325.634 | 3.7672 | 154.126 | 9.574414063 |
| 8 | 199447.33 | 3.4988 | 168.01 | 9.599609375 |
nghttpd
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 205405.524 | 5.6562 | 91.77 | 14.84101563 |
| 2 | 198241.198 | 3.7884 | 104.036 | 12.01835938 |
| 4 | 195620.47 | 3.8596 | 115.082 | 12.3109375 |
| 8 | 192671.3117 | 3.5740383 | 118.5828333 | 11.59673754 |
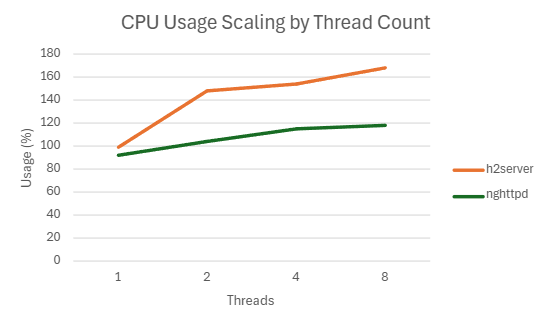
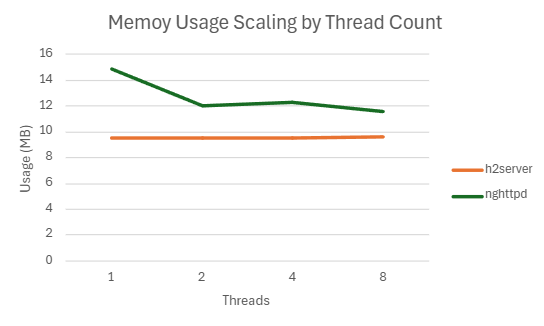
2) h2load -c1000 -m100
h2server
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 221886.068 | 514.821 | 99.938 | 96.4296875 |
| 2 | 410807.138 | 274.1966 | 193.756 | 94.84179688 |
| 4 | 428543.664 | 154.3328 | 219.22 | 91.43515625 |
| 8 | 429380 | 144.1536 | 225.902 | 81.98554688 |
nghttpd
| Threads | QPS | P99 Latency (ms) | CPU Usage (%) | Mem Usage (MB) |
|---|---|---|---|---|
| 1 | 375828.332 | 254.2466 | 91.048 | 75.29472656 |
| 2 | 377719 | 243.6276 | 87.612 | 75.25371094 |
| 4 | 400143.366 | 241.7932 | 90.768 | 75.19921875 |
| 8 | 352529.364 | 264.8662 | 85.352 | 75.21660156 |
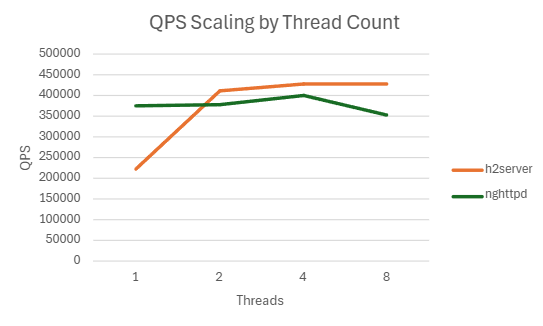
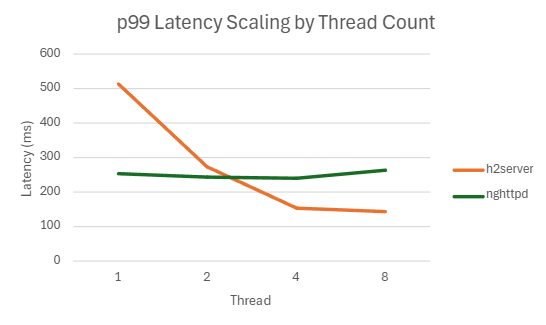
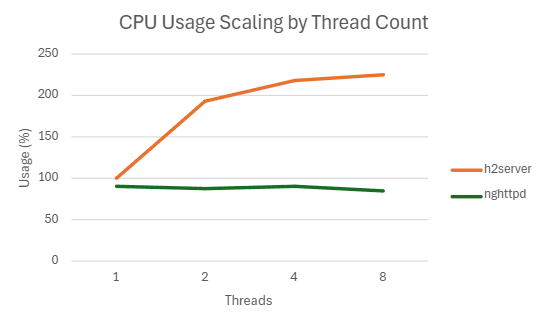
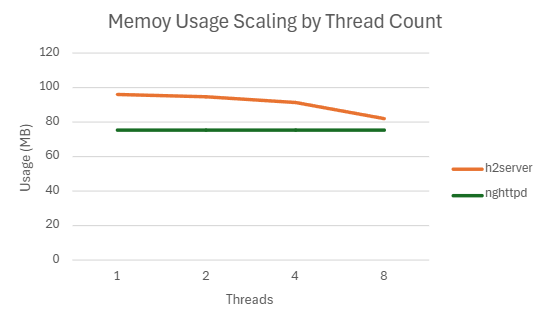
4.3. static-partitioning 브랜치 도입 배경
origin 브랜치에서는 acceptor → load balancer → worker 구조를 통해
HTTP/2 세션 처리, TLS 처리, 파일 서비스, 멀티스레드 분산 구조의 기본 타당성을 검증했다.
실제로 고부하 멀티스레드 환경에서 h2server는 nghttpd 대비 더 나은 확장성을 보였고, 특히 4~8 스레드 구간에서 처리량과 p99 latency 측면에서 의미 있는 결과를 확인할 수 있었다.
다만 구조를 발전시키는 과정에서, readiness 중심의 처리 추상화가 모든 경로에 동일하게 최적은 아니라는 점도 보이기 시작했다. 특히 H2C 경로에서는 워커 책임과 처리 경로를 더 명확히 분리하고, 이벤트를 단순 readiness가 아니라 completion에 가깝게 다루는 방식이 고부하에서 더 유리할 수 있다고 판단했다.
이 문제의식을 바탕으로 static-partitioning 브랜치를 별도로 구성했다.
이 브랜치의 목표는 단순 기능 추가가 아니라,
- 워커의 책임을 더 명확히 나누고,
- 처리 경로를 더 고정적이고 단순하게 만들며,
- H2C 경로에서 completion 모델을 적용해 실제 처리량(QPS)과 스레드 확장성이 얼마나 개선되는지를 검증하는 데 있었다.
4.3.1. static-partitioning 구조
acceptor → load balancer → worker 구조가 람다를 이용하여 컴파일 타임에 TLS ON/OFF 여부에 따라 소켓 연결 이후의 처리 경로(H2 처리 or H2C 처리)를 함수 포인터 처럼 바인딩 해놓고 런타임 때 실체를 생성 되도록 한 구조라면,
static-partitioning구조는 소켓 연결 이후의 처리 경로를 실행 모드별로 컴파일 타임에 템플릿을 이용하여 명확하게 분리되어 빌드 되도록 한 구조이다.
origin 브랜치가 acceptor → load balancer → worker 구조 안에서 공통적인 worker 처리 흐름을 중심으로 확장성을 검증했다면, static-partitioning 브랜치는 그 위에서 H2(TLS), H2C(epoll), H2C(io_uring) 경로를 서로 다른 워커 구현과 이벤트 처리 방식으로 분리해 고부하 상황에서 각 경로의 특성에 맞는 처리 모델을 실험하는 데 초점을 두었다.
즉, 이 브랜치의 핵심은 “프로토콜/실행 모드별 처리 경로를 덜 섞고 더 고정적으로 운영하는 것”에 가깝다.
특히 H2C 경로에서는 epoll 기반 readiness 모델과 io_uring 기반 completion 모델을 나누어 비교함으로써, 고부하 구간에서의 처리량 차이를 직접 검증했다.
4.4. static-partitioning 최신 벤치마크
Ubuntu 24.04 업그레이드 이후의 static-partitioning 기준 성능 측정에서는,
프로파일링 도구 자체의 오버헤드를 줄이기 위해 h2load만 사용하여 QPS 중심으로 비교했다.
즉, 이 섹션은 origin에서의 상세한 latency/CPU/memory 분석을 대체하기보다는,
최신 구조에서의 처리량과 스레드 확장성 변화를 빠르게 확인하는 데 목적이 있다.
테스트 환경
- Host OS: Windows 11
- Host CPU: AMD Ryzen 5 7500F
- Virtualization: VMware Workstation Pro
- Guest OS: Ubuntu 24.04
- Server 4 cores / Client 2 cores
- Clients: 1000
- Max Streams: 100
- Duration: 60s
- Warm-up: 5s
- Repeat: 5 runs
Average QPS
| Threads | nghttpd h2 | nghttpd h2c | h2server h2 | h2server h2c | h2server h2c-io-uring |
|---|---|---|---|---|---|
| 1 | 237,691.400 | 265,844.880 | 204,269.332 | 231,736.878 | 215,849.772 |
| 2 | 357,122.614 | 415,930.222 | 281,325.252 | 313,524.066 | 406,326.790 |
| 4 | 374,448.666 | 457,900.000 | 426,418.254 | 555,360.632 | 553,962.568 |
| 8 | 402,795.666 | 454,465.334 | 408,376.000 | 538,905.998 | 546,887.852 |
Max QPS
| Threads | nghttpd h2 | nghttpd h2c | h2server h2 | h2server h2c | h2server h2c-io-uring |
|---|---|---|---|---|---|
| 1 | 274,885.750 | 279,853.330 | 234,428.330 | 245,015.670 | 218,185.600 |
| 2 | 417,983.830 | 473,583.330 | 299,750.000 | 326,406.670 | 421,581.880 |
| 4 | 417,850.000 | 507,730.000 | 461,459.470 | 585,625.000 | 582,921.700 |
| 8 | 406,971.670 | 498,368.330 | 417,993.330 | 597,368.330 | 605,540.000 |
요약
이 결과에서 가장 눈에 띄는 점은 다음과 같다.
- 4스레드 이상 구간에서
h2server h2c및h2server h2c-io-uring이nghttpd를 추월 - 최고 성능은
h2server_h2c_io_uring_n8 - 최대 QPS는 605,540
- 정적 분리(static partitioning)와 completion 모델이 고부하 구간에서 의미 있는 처리량 개선을 보여줌
4.5. origin과 static-partitioning 비교 해석
origin 브랜치의 목표는 HTTP/2 서버의 기본 골격을 직접 설계하고,
acceptor → worker 분리, 로드 밸런싱, mmap 파일 캐시, 사용자 라우팅, TLS/H2C 지원 같은 핵심 구성 요소가 실제로 어느 정도의 성능과 확장성을 보이는지 확인하는 데 있었다.
실제로 origin 계열의 벤치마크에서는 멀티스레드 구간에서 nghttpd 대비 더 나은 확장성과 더 낮은 p99 latency를 확인할 수 있었고, H2C 8스레드 기준 약 429K QPS 수준까지 도달했다.
반면 static-partitioning 브랜치는 그 다음 단계의 실험이다.
이미 기본 골격이 검증된 상태에서, 워커 책임과 처리 경로를 더 명확히 분리하고 H2C 경로에 completion 모델을 도입함으로써, 고부하 환경에서의 throughput을 얼마나 더 끌어올릴 수 있는지를 확인하는 데 초점을 맞췄다.
그 결과 최신 기준에서는 h2server h2c-io-uring이 8스레드에서 605,540 QPS를 기록하며, origin 대비 한 단계 더 높은 처리량을 달성했다.
즉, 이 프로젝트의 흐름은
기본 구조 검증(origin) → 처리 경로 고정화 및 고부하 최적화(static-partitioning)
로 이해하는 것이 가장 자연스럽다.
5. 정리
이 프로젝트는 단순히 HTTP/2 기능을 구현하는 데서 끝나지 않고,
고성능 서버 구조를 실제로 설계하고 측정하면서 어디에서 병목이 생기고 어떤 아키텍처 선택이 throughput과 latency에 영향을 주는지를 검증하기 위한 실험 프로젝트로 발전해 왔다.
origin 브랜치에서는 acceptor → load balancer → worker 구조, mmap 캐시, TLS/H2C 처리, Router 분리, 멀티스레드 확장성을 중심으로 서버의 기본 타당성을 검증했다.
그 다음 단계인 static-partitioning 브랜치에서는 워커 책임과 처리 경로를 더 명확히 분리하고, H2C 경로에 completion 모델을 도입해 고부하 환경에서의 확장성을 더 밀어붙였다.
그 결과 최신 측정에서는 h2server_h2c_io_uring_n8 기준 Max QPS 605,540을 기록할 수 있었다.